In practice it’s very systematic for small networks. You perform a search over a range of values until you find what works. We know the optimisation gets harder the deeper a network is so you probably won’t go over 3 hidden layers on tabular data (although if you really care about performance on tabular data you would use something that wasn’t a neural network).
But yes, fundamentally, it’s arbitrary. For each dataset a different architecture might work better, and no one has a good strategy for picking it.
It is random, at least while it is learning. It would have most likely tried 5 layers, or even 50.
But the point is to simplify it enough while still working the way it should. And when maximizing the efficiency, you generally get only a handful of efficient ways your problem can be solved.

{kind=link}
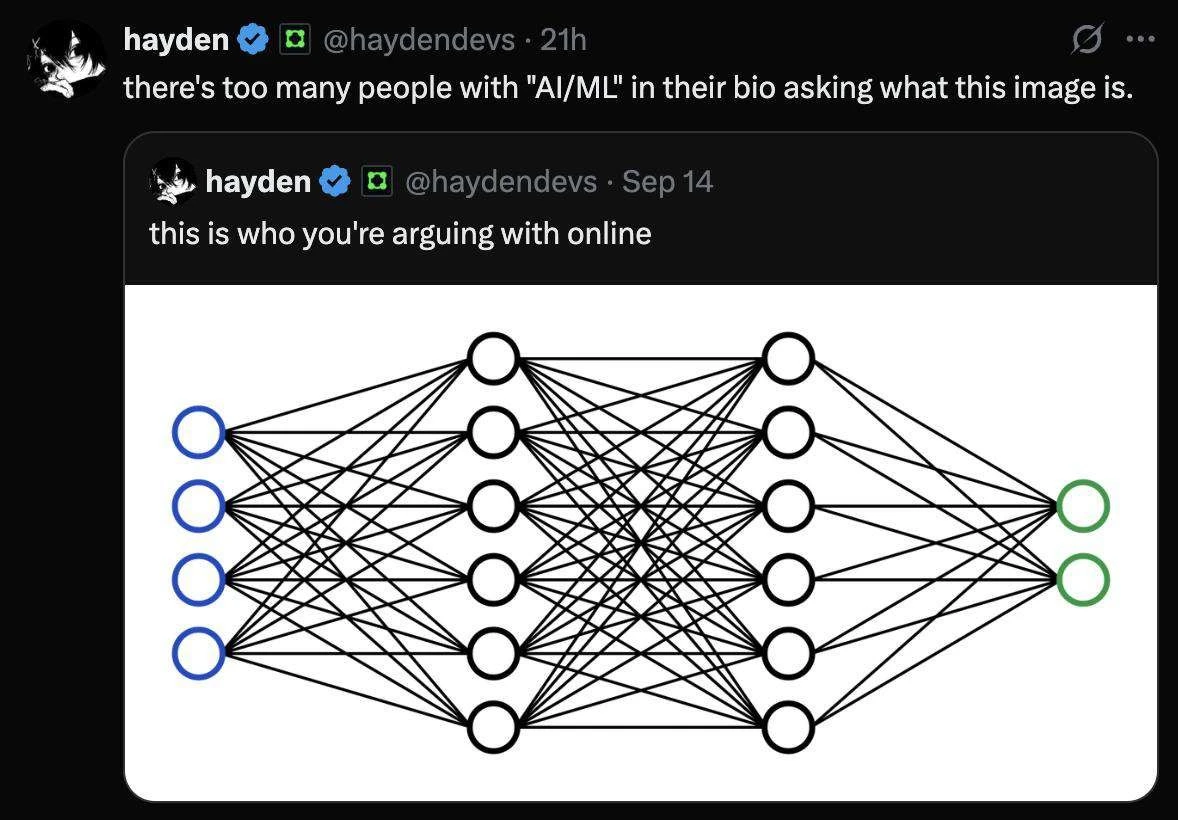
All seems pretty random, and not very scientific. Why not try 5 layers, or 50, 500? A million nodes? It’s just a bit arbitrary.
In practice it’s very systematic for small networks. You perform a search over a range of values until you find what works. We know the optimisation gets harder the deeper a network is so you probably won’t go over 3 hidden layers on tabular data (although if you really care about performance on tabular data you would use something that wasn’t a neural network).
But yes, fundamentally, it’s arbitrary. For each dataset a different architecture might work better, and no one has a good strategy for picking it.
There are ways to estimate a little more accurately, but the amount of fine tuning that is guesswork and brute force searching is too damn high…
It is random, at least while it is learning. It would have most likely tried 5 layers, or even 50.
But the point is to simplify it enough while still working the way it should. And when maximizing the efficiency, you generally get only a handful of efficient ways your problem can be solved.